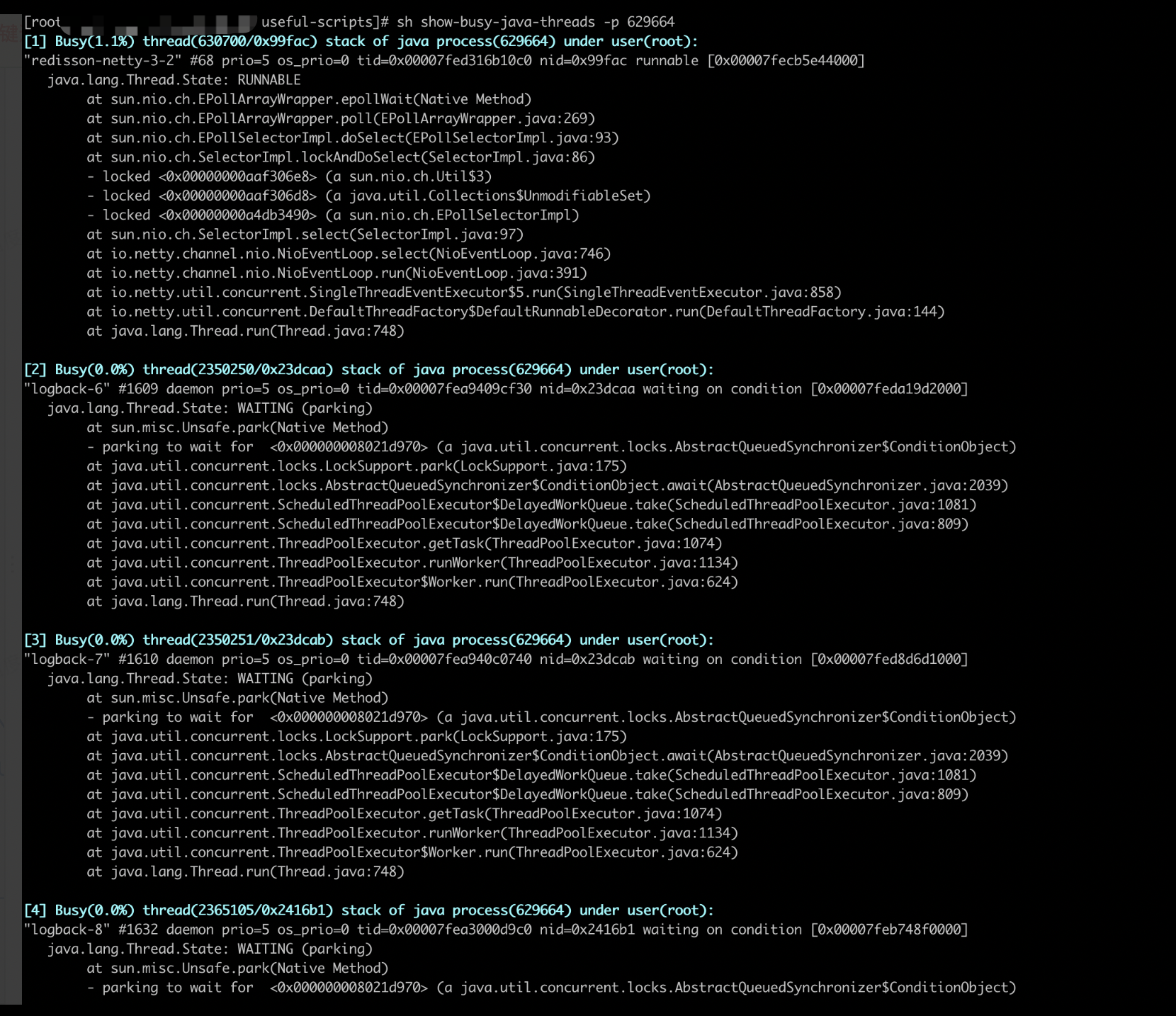
BIO,同步阻塞式IO,简单理解:一个连接一个线程(适合稳定少数连接)
NIO,同步非阻塞IO,简单理解:一个请求一个线程: 标准/典型的Reactor(适合大量短链接)
AIO,异步非阻塞IO,简单理解:一个有效请求一个线程:改进实现的Proactor(适合长重操作,代价是新启线程)
BIO里用户最关心"我要读",NIO里用户最关心"我可以读了",在AIO模型里用户更需要关注的是"读完了"。
概念 NIO
本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题: 在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。 (用内核基于事件回掉机制一个线程轮询,代替大量线程阻塞)
JDK中 nio模型
在jdk中ServerSocketChannel(ServerSocket用于接收请求事件)、SocketChannel(socket读、写)、Selector(通道选择器)、ByteBuffer等API
AIO
与NIO不同,当进行读写操作时,只须直接调用API的read或write方法即可。这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序。
即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数。
在JDK1.7中,这部分内容被称作NIO.2,主要在java.nio.channels包下增加了下面四个异步通道:
AsynchronousSocketChannel
AsynchronousServerSocketChannel
AsynchronousFileChannel
AsynchronousDatagramChannel
其中的read/write方法,会返回一个带回调函数的对象,当执行完读取/写入操作后,直接调用回调函数。
实现原理 说道实现原理,还要从操作系统的IO模型上了解
按照《Unix网络编程》的划分,IO模型可以分为:阻塞IO、非阻塞IO、IO复用、信号驱动IO和异步IO,按照POSIX标准来划分只分为两类:同步IO和异步IO。如何区分呢?首先一个IO操作其实分成了 两个步骤:发起IO请求和实际的IO操作,同步IO和异步IO的区别就在于第二个步骤是否阻塞,如果实际的IO读写阻塞请求进程,那么就是同步IO ,因此阻塞IO、非阻塞IO、IO复用、信号驱动IO都是同步IO,如果不阻塞,而是操作系统帮你做完IO操作再将结果返回给你,那么就是异步IO。阻塞IO和非阻塞IO的区别在于第一步,发起IO请求是否会被阻塞,如果阻塞直到完成那么就是传统的阻塞IO,如果不阻塞,那么就是非阻塞IO。( 因此可以大胆猜测理解jdk AIO异步模型是基于api层事件驱动实现+NIO )
操作系统io模型
说到操作系统的IO模型,又不得不提select/poll/epoll/iocp
首先我们来定义流的概念,一个流可以是文件,socket,pipe等等可以进行I/O操作的内核对象。
不管是文件,还是套接字,还是管道,我们都可以把他们看作流。
之后我们来讨论I/O的操作,通过read,我们可以从流中读入数据;通过write,我们可以往流写入数据。现在假定一个情形,我们需要从流中读数据,但是流中还没有数据,(典型的例子为,客户端要从socket读如数据,但是服务器还没有把数据传回来),这时候该怎么办?
阻塞。阻塞是个什么概念呢?比如某个时候你在等快递,但是你不知道快递什么时候过来,而且你没有别的事可以干(或者说接下来的事要等快递来了才能做);那么你可以去睡觉了,因为你知道快递把货送来时一定会给你打个电话(假定一定能叫醒你)。
为了了解阻塞是如何进行的,我们来讨论缓冲区,以及内核缓冲区,最终把I/O事件解释清楚。缓冲区的引入是为了减少频繁I/O操作而引起频繁的系统调用(你知道它很慢的),当你操作一个流时,更多的是以缓冲区为单位进行操作,这是相对于用户空间而言。对于内核来说,也需要缓冲区。
假设有一个管道,进程A为管道的写入方,B为管道的读出方。
假设一开始内核缓冲区是空的,B作为读出方,被阻塞着。然后首先A往管道写入,这时候内核缓冲区由空的状态变到非空状态,内核就会产生一个事件告诉B该醒来了,这个事件姑且称之为"缓冲区非空"。
但是"缓冲区非空"事件通知B后,B却还没有读出数据;且内核许诺了不能把写入管道中的数据丢掉这个时候,A写入的数据会滞留在内核缓冲区中,如果内核也缓冲区满了,B仍未开始读数据,最终内核缓冲区会被填满,这个时候会产生一个I/O事件,告诉进程A,你该等等(阻塞)了,我们把这个事件定义为"缓冲区满"。
假设后来B终于开始读数据了,于是内核的缓冲区空了出来,这时候内核会告诉A,内核缓冲区有空位了,你可以从长眠中醒来了,继续写数据了,我们把这个事件叫做"缓冲区非满"
也许事件Y1已经通知了A,但是A也没有数据写入了,而B继续读出数据,知道内核缓冲区空了。这个时候内核就告诉B,你需要阻塞了!,我们把这个时间定为"缓冲区空"。
这四个情形涵盖了四个I/O事件, 缓冲区满,缓冲区空,缓冲区非空,缓冲区非满 (注都是说的内核缓冲区,且这四个术语都是我生造的,仅为解释其原理而造)。这四个I/O事件是 进行阻塞同步的根本,也是NIO模型被提出使用的原因 。(如果不能理解"同步"是什么概念,请学习操作系统的锁,信号量,条件变量等任务同步方面的相关知识)。
然后我们来说说阻塞I/O的缺点。但是阻塞I/O模式下,一个线程只能处理一个流的I/O事件。如果想要同时处理多个流,要么多进程(fork),要么多线程(pthread_create),很不幸这两种方法效率都不高。
于是再来考虑非阻塞忙轮询的I/O方式,我们发现我们可以同时处理多个流了(把一个流从阻塞模式切换到非阻塞模式再此不予讨论):
1 2 3 4 5 6 while true { for i in stream[]; { if i has data read until unavailable } }
我们只要不停的把所有流从头到尾问一遍,又从头开始。这样就可以处理多个流了,但这样的做法显然不好,因为如果所有的流都没有数据,那么只会白白浪费CPU。这里要补充一点,阻塞模式下,内核对于I/O事件的处理是阻塞或者唤醒,而非阻塞模式下则把I/O事件交给其他对象(后文介绍的select以及epoll)处理甚至直接忽略。
为了避免CPU空转,可以引进了一个代理(一开始有一位叫做select的代理,后来又有一位叫做poll的代理,不过两者的本质是一样的)。这个代理比较厉害,可以同时观察许多流的I/O事件,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中醒来,于是我们的程序就会轮询一遍所有的流(于是我们可以把"忙"字去掉了)。代码长这样:
1 2 3 4 5 6 7 while true { select(streams[]) for i in streams[] { if i has data read until unavailable } }
于是,如果没有I/O事件产生,我们的程序就会阻塞在select处。但是依然有个问题,我们从select那里仅仅知道了,有I/O事件发生了,但却并不知道是那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。
但是使用select,我们有O(n)的无差别轮询复杂度,同时处理的流越多,每一次无差别轮询时间就越长。再次
说了这么多,终于能好好解释epoll了
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll之会把哪个流发生了怎样的I/O事件通知我们。此时我们对这些流的操作都是有意义的。(复杂度降低到了O(k),k为产生I/O事件的流的个数,也有认为O(1)的[更新 1])
在讨论epoll的实现细节之前,先把epoll的相关操作列出[更新 2]:
epoll_create 创建一个epoll对象,一般epollfd = epoll_create()
epoll_ctl (epoll_add/epoll_del的合体),往epoll对象中增加/删除某一个流的某一个事件
比如
epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);//有缓冲区内有数据时epoll_wait返回
epoll_ctl(epollfd, EPOLL_CTL_DEL, socket, EPOLLOUT);//缓冲区可写入时epoll_wait返回
epoll_wait(epollfd,…)等待直到注册的事件发生
(注:当对一个非阻塞流的读写发生缓冲区满或缓冲区空,write/read会返回-1,并设置errno=EAGAIN。而epoll只关心缓冲区非满和缓冲区非空事件)。
一个epoll模式的代码大概的样子是:
1 2 3 4 5 6 while true {active\_stream[] = epoll\_wait(epollfd) for i in active\_stream[] { read or write till unavailable } }
简单的的画了下自己理解的概念草图:
select/epoll白话文总结:select/epoll进程首先会copy所有对应等待的文件描述符fd(理解为文件指针的指针,select 1024,epoll无限制),当内核发现当前缓冲区满或空时触发一个i/o响应中断,告诉select/epoll进程,对于select来讲只是被告知触发的fd数,需要内核再次遍历下所有fd,然后返回可用fd并copy至用户态,下次发起select时会再次copy,与epoll不同的是,内核在poll时会回调epoll告诉具体可用fd,并存储在epoll维护的一个list里(基于红黑树)然后直接将可用list copy至用户态,并且在下次发起系统调用时,不需要再次进行第一次的fd copy.
可以理解的说明是:在Linux 2.6以后,java NIO的实现,是通过epoll来实现的,这点可以通过jdk的源代码发现。而AIO,在windows上是通过IOCP实现的,在linux上还是通过epoll来实现的,目前除了windows操作系统还不提供这种异步io实现机制。
这里强调一点:AIO,这是I/O处理模式,而epoll等都是实现AIO的一种编程模型;换句话说,AIO是一种接口标准,各家操作系统可以实现也可以不实现。在不同操作系统上在高并发情况下最好都采用操作系统推荐的方式。Linux上还没有真正实现网络方式的AIO。
底层基础 :
AIO实现
在windows上,AIO的实现是通过IOCP来完成的,看JDK的源代码,可以发现
WindowsAsynchronousSocketChannelImpl
看实现接口:
implements Iocp.OverlappedChannel
再看实现方法:里面的read0/write0方法是native方法,调用的jvm底层实现。
在linux上,AIO的实现是通过epoll来完成的,看JDK源码,可以发现,实现源码是:
UnixAsynchronousSocketChannelImpl
看实现接口:
implements Port.PollableChannel
这是与windows最大的区别,poll的实现,在linux2.6后,默认使用epoll。
NIO对应Buffer的选择
对于NIO来说,缓存的使用可以使用DirectByteBuffer和HeapByteBuffer。如果使用了DirectByteBuffer,一般来说可以减少一次系统空间到用户空间的拷贝。但Buffer创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能。如果数据量比较小的中小应用情况下,可以考虑使用heapBuffer;反之可以用directBuffer。
堆外内存有以下特点:
对于大内存有良好的伸缩性,不受JVM gc控制适合保存长久对象 用户session等
在进程间可以共享,减少虚拟机间的复制
创建开销大,不受JVM管控,内存回收时通过DirectByteBuffer在jvm中引用回收时被回收。
NIO存在的问题 使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。
NIO并没有完全屏蔽平台差异,它仍然是基于各个操作系统的I/O系统实现的,差异仍然存在。使用NIO做网络编程构建事件驱动模型并不容易,陷阱重重。
推荐大家使用成熟的NIO框架,如Netty,MINA等。解决了很多NIO的陷阱,并屏蔽了操作系统的差异,有较好的性能和编程模型。
epoll惊群:
惊群主要还是指在多线程共享一个epoll fd的时候,如果epoll_wait所等待的fd(比如一条tcp连接可读)有事件发生时,epoll不知道唤醒哪个线程,就会把所有线程都唤醒,但是最终只有一个线程能去处理,其他的线程都会返回。如果不是多线程共享一个epoll,那就不会有这样的问题。
Ngnix 的解决方法
Ngnix 目前有几种方法解决惊群问题。
accept_mutex 锁
如果开启了accept_mutex锁,每个 worker 都会先去抢自旋锁,只有抢占成功了,才把 socket 加入到 epoll 中,accept 请求,然后释放锁。accept_mutex锁也有负载均衡的作用。
accept_mutex效率低下,特别是在长连接的时候。因为长连接时,一个进程长时间占用accept_mutex锁,使得其它进程得不到 accept 的机会。因此不建议使用,默认是关闭的。
EPOLLEXCLUSIVE 标识
EPOLLEXCLUSIVE是4.5+内核新添加的一个 epoll 的标识,Ngnix 在 1.11.3 之后添加了NGX_EXCLUSIVE_EVENT。
EPOLLEXCLUSIVE标识会保证一个事件发生时候只有一个线程会被唤醒,以避免多侦听下的"惊群"问题。不过任一时候只能有一个工作线程调用 accept,限制了真正并行的吞吐量。
SO_REUSEPORT 选项
SO_REUSEPORT 是惊群最好的解决方法,Ngnix 在 1.9.1 中加入了这个选项,每个 worker 都有自己的 socket,这些 socket 都bind同一个端口。当新请求到来时,内核根据四元组信息进行负载均衡,非常高效。
LT DT:JDK水平触发,Netty边缘触发
netty jdk epoll bug
空轮询情况即:selector.select(timeoutMillis)操作会立即返回,不会阻塞timeoutMillis,导致 currentTimeNanos 几乎不变,这种情况下,会反复执行selector.select(timeoutMillis),变量selectCnt 会逐渐变大,当selectCnt 达到阈值,则执行rebuildSelector方法,进行selector重建,将出现bug的Selector上的channel重新注册到新的Selector上,解决cpu占用100%的bug。
Netty 解决TCP粘包拆包问题
为了解决TCP粘包、拆包导致的半包读写问题,Netty默认提供了多种编解码器用于处理半包,或者可以根据实际情况自行实现ChannelHandler来定制自己的应用协议栈,一般可以直接实现ByteToMessageDecoder。使用时只需要将需要的编解码器添加到channel的责任链上即可,Netty处理粘包拆包问题的核心思路就是:每次读取的时候,如果能读取到一个完整的数据包,才真正读取出来,一直读到没有数据可读,如果有半包消息,则保存下来未处理的半包消息,下次读事件触发的时候,将未处理的半包消息和新的消息内容合并在一起再继续处理。最后将所有解析出来的完整数据包依次进行fireChannelRead事件的传播,进行后续的业务处理。
接下来我会整理Tomcat servlet相关服务器模型、NIO在Netty中实战,及Netty在dubbo、zk中应用。
参考:
https://www.jianshu.com/p/db5da880154a
https://tech.meituan.com/nio.html
/image-20220419102819294.png)
/image-20220419102848954.png)
/image-20220419102957374.png)
/image-20220419103013594.png)
/image-20220419103543797.png)
/image-20220419103445191.png)